


- Your audio uploaded to a third-party cloud
- API keys, accounts, and per-minute fees
- A black-box job you can't script around
- Your data living on someone else's server
← All projects Transcription Studio · Open source
Paste a link. Get a transcript. Your audio never leaves your machine.
A self-hosted transcription service from FCT — a FastAPI backend running Faster-Whisper locally, with a one-link UI and a JSON API. No cloud, no API keys, no third party touching your audio.
Why it exists
Most one-link transcribers upload your audio.
They send your media to someone else's infrastructure, paywall the model, or both. Transcription Studio is the local-first alternative — the Whisper runtime on your own hardware, behind a clean HTTP contract.
- Everything runs on your own machine
- No keys, no accounts, no usage fees
- A JSON API you can automate against
- Audio never leaves the device
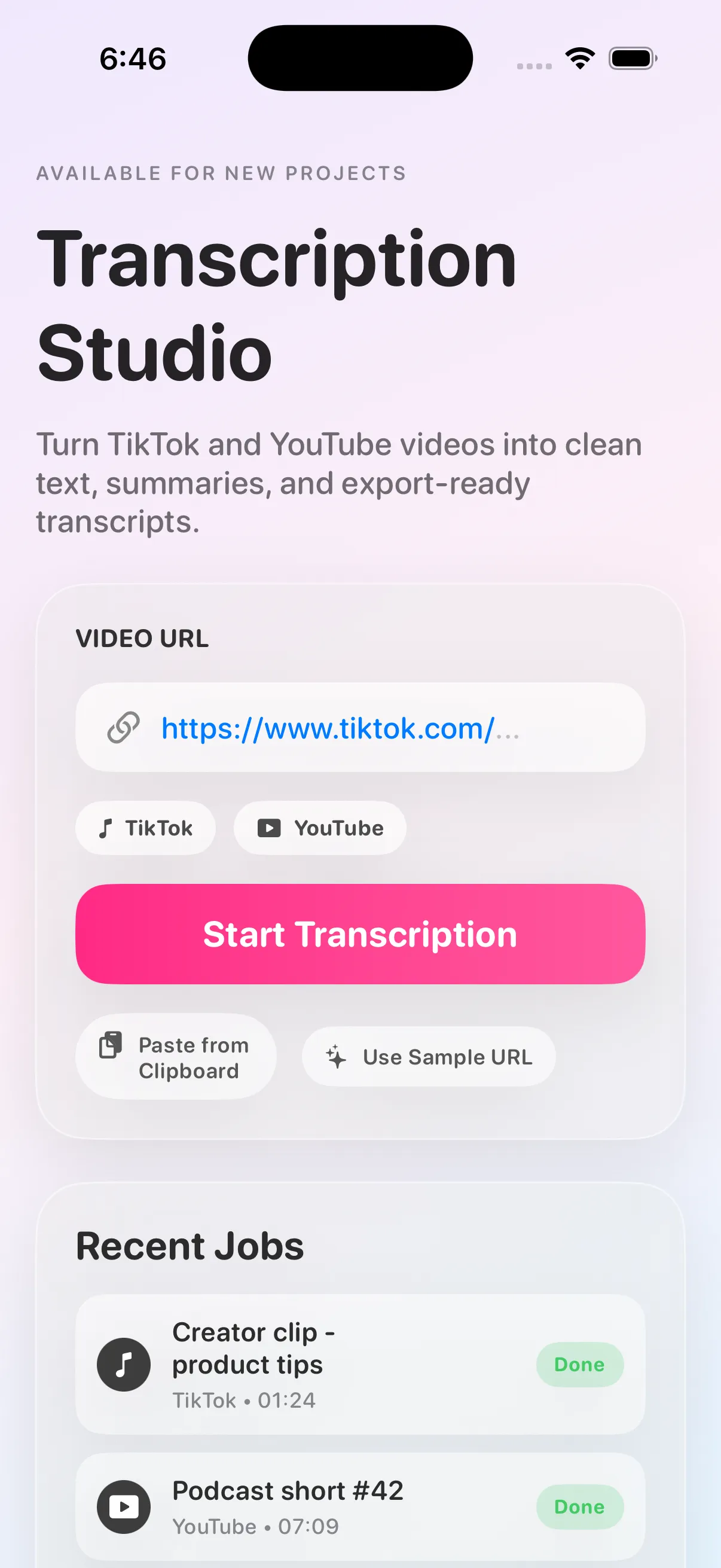
From link to transcript
Three steps, fully local.
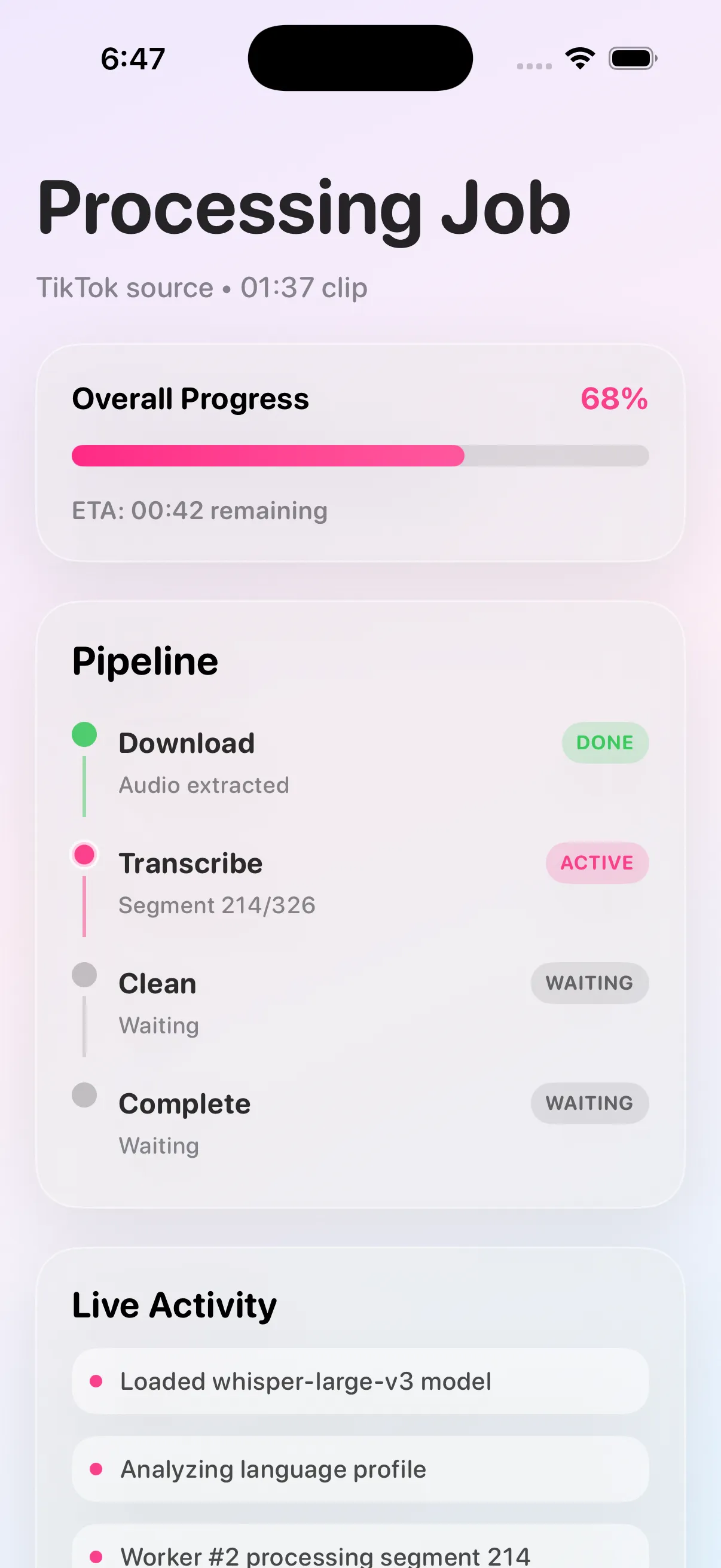
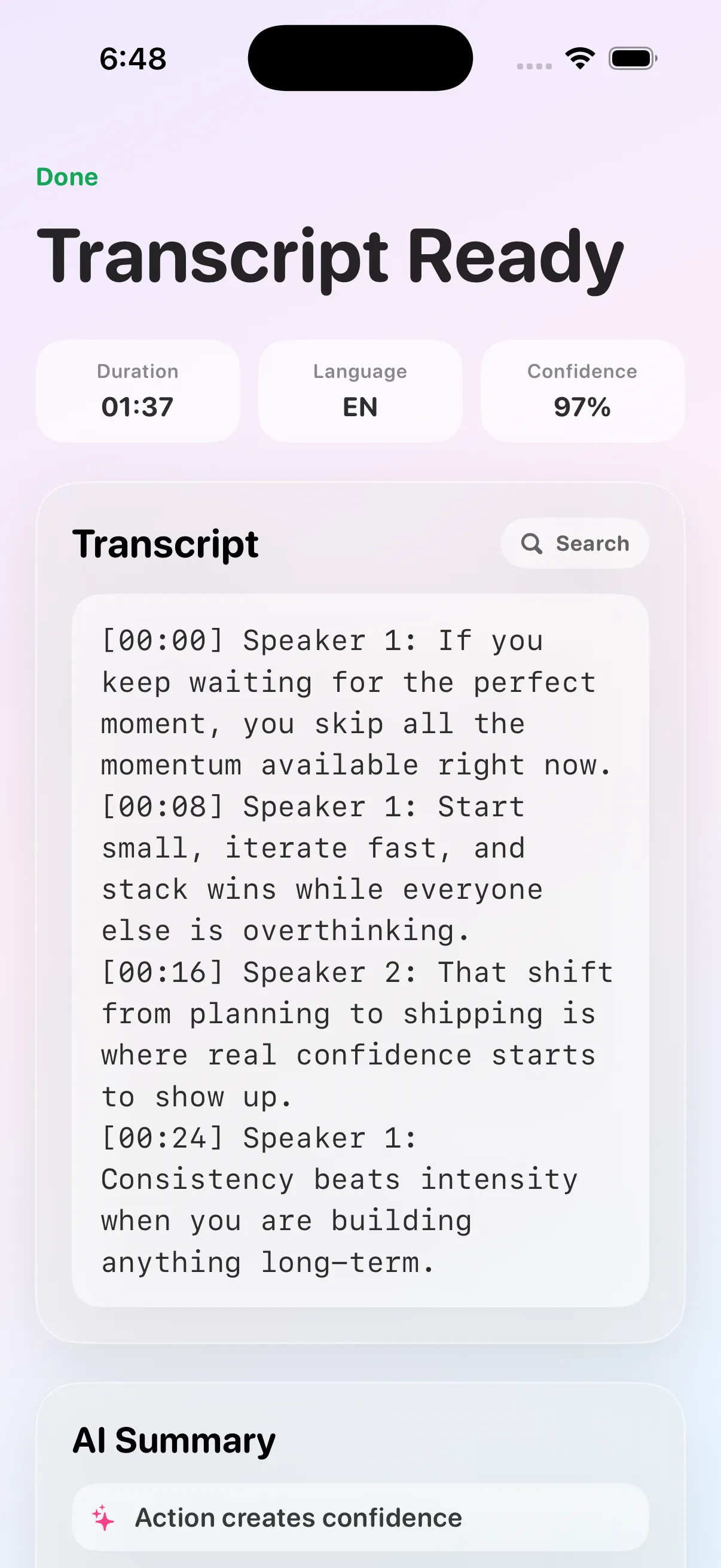
Submit, watch the job run, and get a clean transcript back — with live progress the whole way.
What it proves
Small, honest, and built to integrate.
The architectural lessons matter as much as the product: clear stage boundaries, deterministic state, and config through environment variables so the same code runs anywhere.
Local-first by default
yt-dlp, FFmpeg, and Faster-Whisper all run on your machine. No cloud provider, no API key, no audio leaving the device.
Runs on a Mac mini
Faster-Whisper with int8 quantization runs base.en comfortably on 16 GB — no GPU required.
Two ingestion paths
Async URL jobs polled to completion, plus inline file uploads that return the transcript directly.
Honest job lifecycle
Deterministic states — queued → downloading → transcribing → done — keep the progress bar honest and give integrations a clear contract.
Configurable model lifecycle
Load-on-demand with idle release keeps RAM free; warm and eager modes for latency-sensitive setups.
API-first
The same backend serves the local UI and powers FCT's internal media workflows. Scriptable JSON in, transcript out.
FAQ
Transcription Studio, answered
01 What is Transcription Studio?
Transcription Studio is a self-hosted transcription service from FCT Technologies that turns a link or a media file into a clean text transcript on your own hardware. You paste a TikTok or YouTube URL — or drop an audio or video file — and the app runs the full pipeline locally: yt-dlp fetches the media, FFmpeg prepares the audio, and Faster-Whisper produces the transcript. It exposes two paths: asynchronous URL jobs you poll to completion through deterministic states — queued, downloading, transcribing, done — and inline file uploads that return the transcript directly. The same FastAPI backend serves both the one-link web UI and a JSON API, so you can use it by hand or script against it. It is open source under the MIT license, runs on macOS, Linux, or Windows, and is comfortable on a 16 GB Mac mini with no GPU required. It also powers FCT's own internal media workflows.
02 Is my audio private with Transcription Studio?
Yes — privacy is the entire point of the project. Unlike typical one-link transcribers that upload your media to a third-party cloud, paywall the model, or both, Transcription Studio runs the whole pipeline on your own machine. yt-dlp, FFmpeg, and Faster-Whisper all execute locally, so your audio never leaves the device and there is no external provider in the loop. There are no API keys to create, no accounts to register, and no per-minute usage fees — you self-host it and own the runtime. Because it is open source under MIT, you can read exactly what the code does and run it on hardware you control, behind your own firewall. That makes it a fit for sensitive recordings — client calls, interviews, internal meetings — where sending the audio to a hosted service is not acceptable. The JSON API lets you automate transcription into your own tools without that data ever touching someone else's server.
03 What do I need to run Transcription Studio?
Transcription Studio is built to run on modest hardware. The reference setup is a 16 GB Mac mini: Faster-Whisper with int8 quantization runs the base.en model comfortably there, with no GPU required, and the same code runs on Linux or Windows just as well. Under the hood it is a FastAPI backend on Python 3.10 or newer, with yt-dlp and FFmpeg handling media download and preparation. The model lifecycle is configurable — load-on-demand with idle release keeps RAM free when you are not transcribing, while warm and eager modes cut latency for setups that need fast turnaround. Everything is configured through environment variables, so the same code runs identically across machines. You clone the repository from GitHub, install the dependencies, and you can self-host it in an afternoon. It is open source under the MIT license, so there are no licensing costs and nothing stopping you from adapting it to your own workflow.
Self-host it in an afternoon.
Open source under MIT — clone it, run it on your own hardware, and keep your audio where it belongs.
FastAPIFaster-Whisperyt-dlpFFmpegPython 3.10+REST / JSON API